
Change Data Capture (CDC) is a technology that continuously scans source data systems for changes, identifies them, and delivers those changes to the data warehouse in real-time, so business intelligence applications access only the most recent data. Traditionally, data warehouses were updated using batch-load techniques, in which entire tables were copied from transactional source systems at fixed intervals and copied to the data warehouse. This introduces a time lag between the most recent and stored data in the data warehouse, while also putting a significant load on transactional databases during batch operations. Change Data Capture technology entails three major benefits:
- Changes in the source systems are delivered to the data warehouse in real-time
- Transactional databases are unaffected because production doesn’t need to be paused
- Load on the network is minimized because only incremental changes are delivered, rather than entire tables
Considering the benefits of CDC technology, it might make sense for you to implement the technology in your data warehouse. This article will shed light on how CDC works, along with the different approaches you can use to meet your business intelligence objectives optimally.
How CDC Works
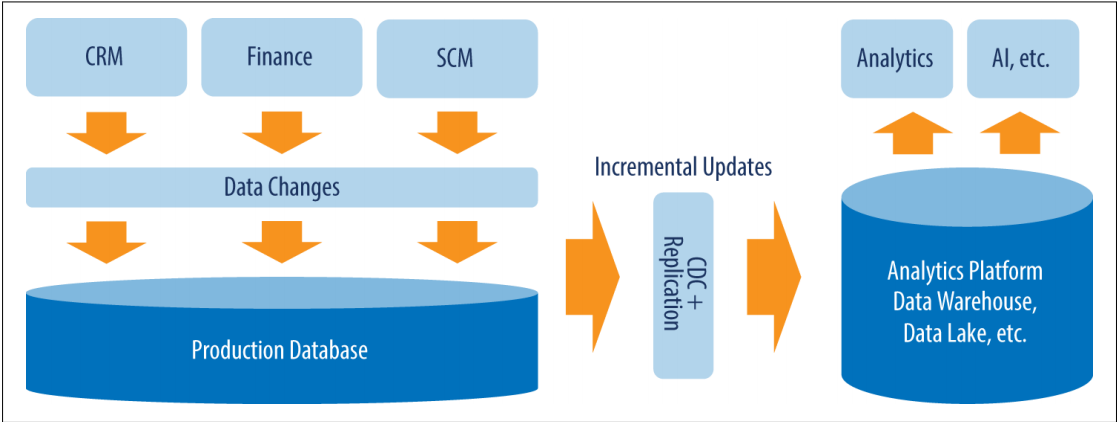
In the simplest terms, CDC records changes made to source tables by flagging INSERT, DELETE, or UPDATE SQL commands.
INSERT: This command adds a new record, or row, to the table. CDC records the newly inserted row and the data it contains.
DELETE: This command is used to delete records and is used in cases when an incorrect transaction needs to be removed, or when the record is no longer relevant.
UPDATE: This command is used to update or modify data in existing records. For instance, a customer address has been changed and needs to be updated.
Any time CDC detects these commands being used in the SQL source database, CDC creates a “change table” that records details of what changed, where the change occurred, and when. Both the actual data in the table, and the metadata are recorded in the “change table” and are delivered to the data warehouse in near-real-time by using ETL incrementally. To record metadata, the change table contains an extra column that lists the nature of change for changed records. The primary benefit here is that load on your infrastructure is minimized because only incremental changes are being delivered to the data warehouse rather than entire tables.
Which CDC Approach is Right for You?
Different source databases allow various methods to record changes. Modern data management tools offer a variety of CDC approaches, each suited to a different use-case. Let’s take a look at some common types of CDC and how they’re implemented:
1. Transaction Logs
Many relational databases maintain a transaction log to keep slave and master databases synced. These logs contain a complete history of INSERT, UPDATE, and DELETE commands and their impact on internal usage. Your solution may be able to use these transaction logs to identify changes for delivery to the data warehouse. However, it’s not that simple. Since transaction logs are in an internal format, each source system could potentially have its own proprietary format for transaction logs. This format may not be usable for CDC and would, therefore, require your IT team to develop different CDC for each source system.
Choose a tool that is extensible and works out a way to capture incremental data on its own, regardless of source and target databases. The right tool will also allow you to apply data transformations automatically so that changed data is ready to be delivered as soon as it is captured.
2. Trigger Tables
Triggers need to be defined to fire off before or after any SQL commands are executed that entail changes. This enables you to create a changelog of your own, rather than relying on source systems’ internal transaction log. Triggers are simply functions that are called before or after INSERT, UPDATE, or DELETE commands are used.
While triggers are more efficient because they operate on the SQL level, they can also require more work because you’d have to develop triggers for each table that you want to be updated in real-time. An alternative can be to opt for a data management solution that allows you to visually specify triggers for different tables, instead of coding triggers separately. While efficient, this approach can only be used if you have access to the source system for implementing triggers.
3. Query-Based CDC
This approach allows you to identify changes by using timestamps, status booleans, version numbers, etc. Query-based CDC is useful when you’re dealing with source systems like Teradata that do not store transaction logs, or when you do not have access to source systems and therefore are unable to implement triggers. Using timestamps, you can identify records that have been changed by comparing the timestamp of the last update with the timestamp of all other rows. If a row has a more recent timestamp, it will be flagged and updated in the data warehouse. While this approach has its benefits, query-based CDC will require you to make changes in the structure of all transaction tables to contain a separate column for timestamp, status, or version.
—
Each CDC approach has its own pros and cons. Schedule a free consultation with our Change Data Capture solution experts to understand which CDC approach is best for your data warehouse environment.




